Gene Expression Omnibus Data Mining (IA): Quick and easy download of GEO data
Data mining is a popular area of bioinformatics analysis. In general, “mining” refers to the acts of retrieving and gathering information from vast amounts of data in order to achieve particular study objectives. The Gene Expression Omnibus (GEO) database is a treasure trove of publicly available microarray and next-generation sequencing data, particularly transcription data. Data mining from GEO enables investigators to analyze differential expression, identify novel relationships or activities, extract significant conclusions, and build frameworks for new avenues of study.
This tutorial series describes the procedures and software tools needed to complete the main steps in the GEO data mining process:
- Search datasets and download data
- Generate expression matrix
- Perform differential analysis
- Identify and visualize differentially expressed genes
- Proceed KEGG and GO enrichment analysis
We begin with the first step, downloading data from GEO. That data will be used subsequently to identify relevant genes and pathways. Initially, the goal is to locate the dataset used in a study of interest and download the corresponding GEO Platform (GPL) file with its expression matrix “series matrix” for gene expression analysis.
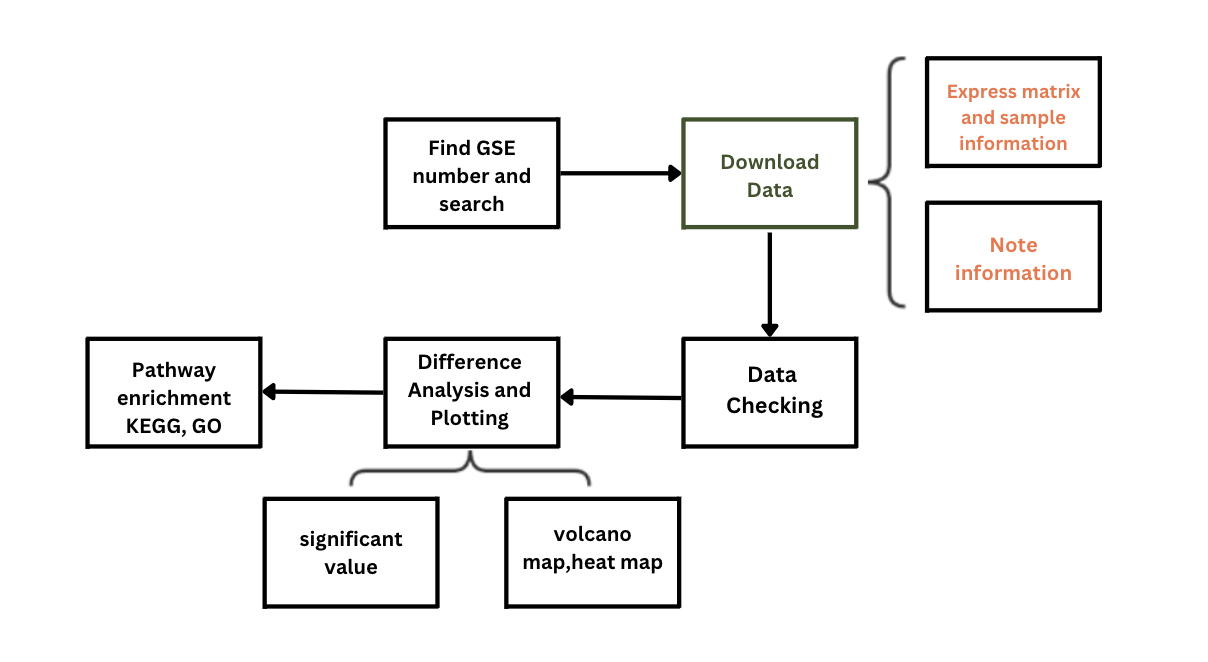
Analysis Process
First, we need a GEO Series (GSE) number to search the GEO website for data of interest. The GSE number should be cited in the relevant research paper. A GEO Series record, which holds all experimental data submitted by an investigator, may include at least one Sample (GSM) record. A published study may have at least one GSE record. Depending on the research goals of a study, multiple GSM records may have been combined into a GEO Dataset (GDS) which are rarely used. Additionally, each Dataset has an associated platform that is GPL-licensed.
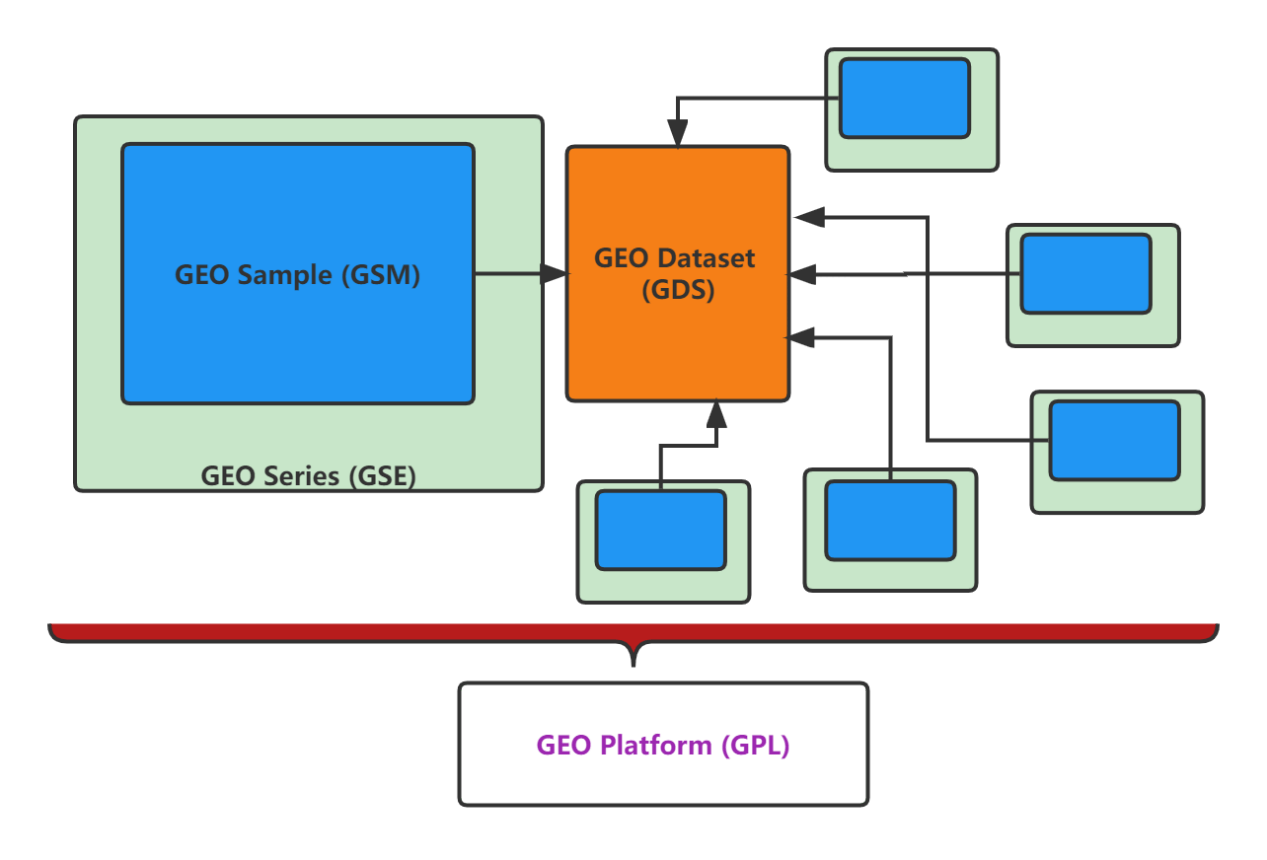
Downloading data from the GEO webpage
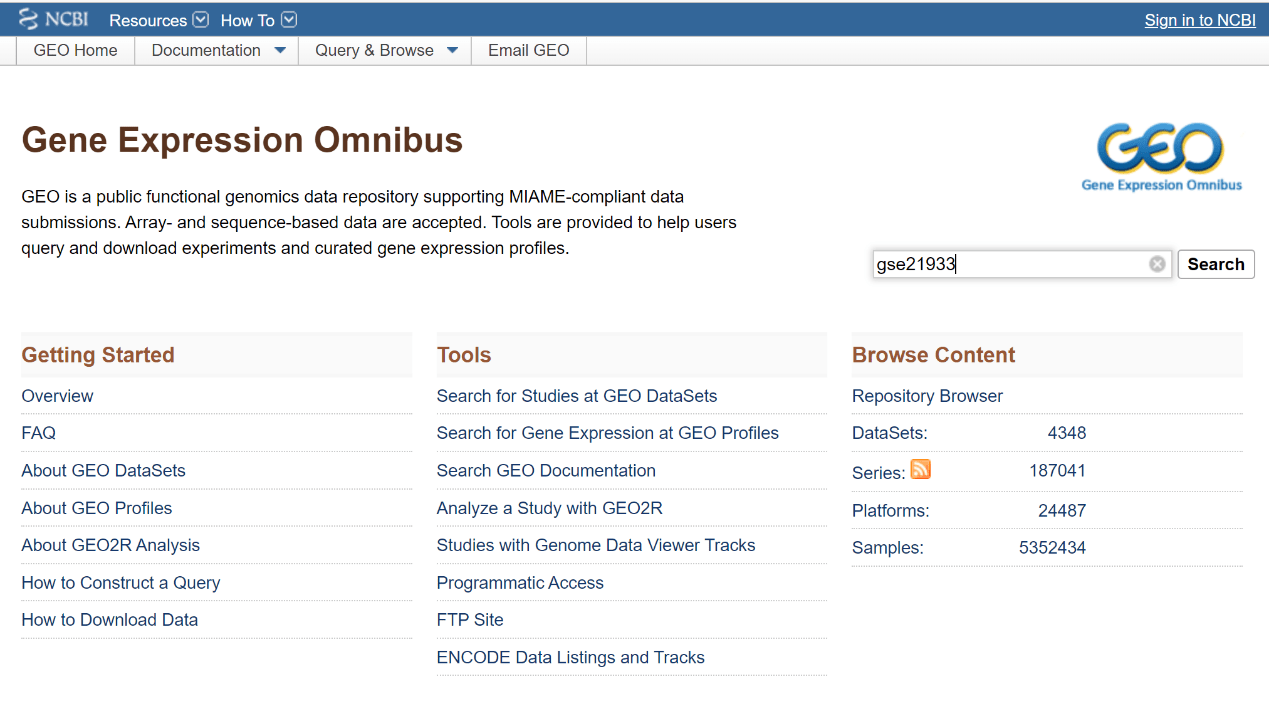
To start, enter into the GEO official website at https://www.ncbi.nlm.nih.gov/geo, log in, and then type a GSE number in the search box (marked in red in the figure below). For example, enter “gse21933” and click “Search” first (1).
The following Accession Display interface includes fundamental GSE data details such as title, species, research summary, author, sample description, and sequencing platform, as well as the raw data.
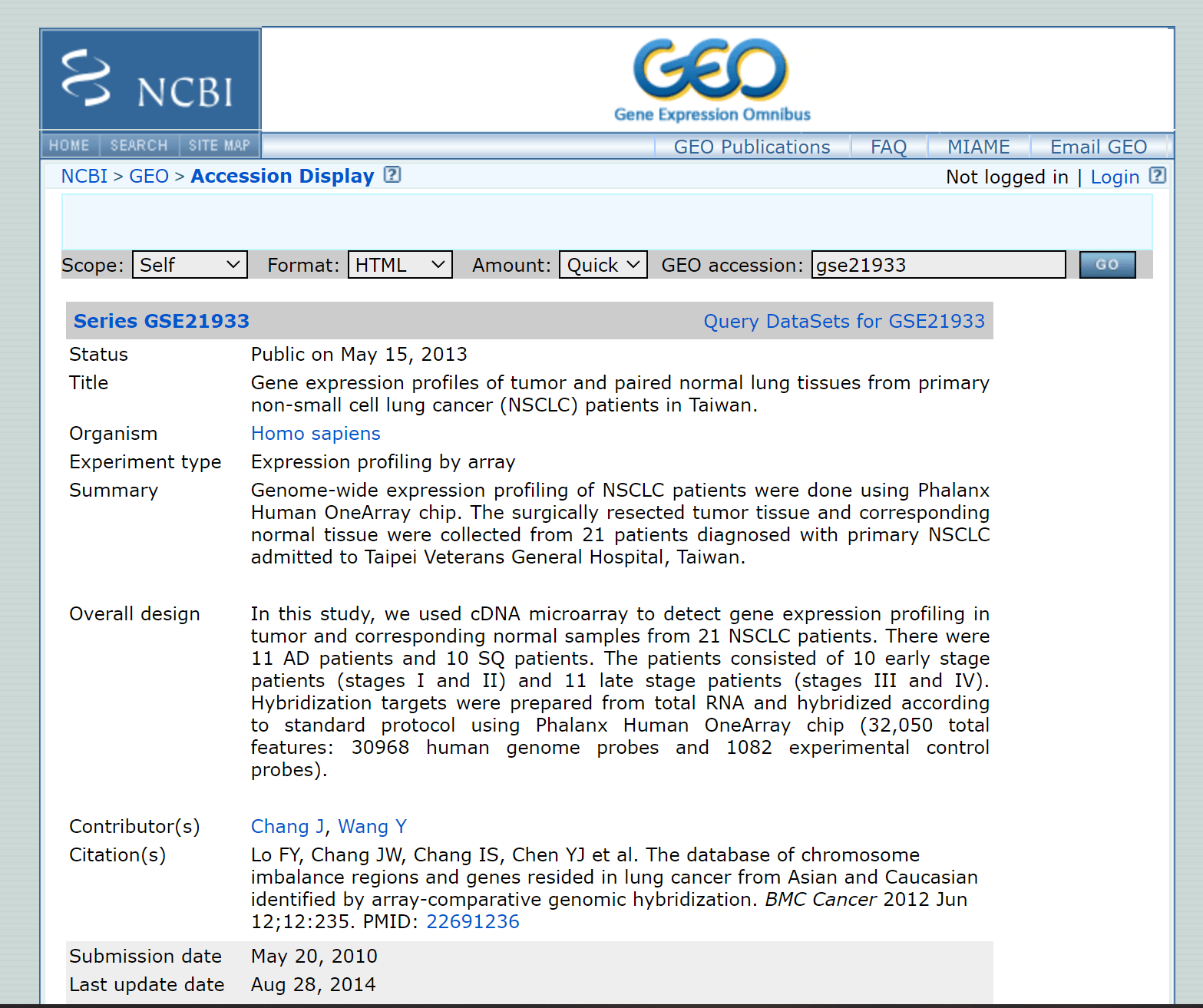
The example data set we have retrieved here (shown in the image above) includes gene expression profiles of lung cancer and healthy tissues. Identifying differentially expressed genes from this data requires three files: the original file, the phenotype file, and the annotation file.
1. The original file contains the expression level of genes in each sample.
As shown in the figure above, the original file is available through a link at the bottom of the page. To download, click on “(http).” The file with tar format needs to be decompressed after downloading.
2. The phenotype file indicates whether each sample belongs to the normal group or to the treatment group. To compare the differences between normal and treatment samples, it is necessary to know the sample type used in each group.

The information about gene expression in samples is stored in the Series Matrix File (gene expression matrix).
3. The annotation files indicate which probe numbers correspond to which genes. Annotation files are necessary to identify the differential genes obtained from raw data processing.

As an analogy, these three categories of data can be thought of as cooking ingredients that are further used with different recipes. In this case the “recipes” are customized data mining analyses performed in accordance with your own demands and research objectives.
Downloading GEO data using an R package
Another option for downloading GEO data is GEOquery, a potent tool for downloading gene data. It is an R program currently hosted by the R open-source website BioConductor (2,3).
Use the following steps to download GEO data with GEOquery:
Download
if (!require(“BiocManager”, quietly = TRUE))
install.packages(“BiocManager”)
BiocManager::install(“GEOquery”)
Call
library(GEOquery)#directlycall
eSet <- getGEO("GSE21933",
destdir = ‘.’,
getGPL = F)
The getGEO function can load the GSE matrix file. The annotation probe information will be downloaded by default, and the probes in the expression matrix will be annotated. However, the annotation file is quite extensive, thereby probably arising parsing preservation issues. To stop the annotation function by setting getGPL=F and manually annotating the data during the subsequent analysis steps are recommended.
Please continue to read the “GEO Data Mining” series of articles if you want to learn more about the ensuing tailored analysis. Downloading raw sequencing data from the Sequence Read Archive (SRA) database will be introduced in the next part.
References:
1.https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=gse21933 (Accessed 12/11)
2.Davis S, Meltzer P (2007). “GEOquery: a bridge between the Gene Expression Omnibus (GEO) and BioConductor.” Bioinformatics, 14, 1846–1847.
3.https://bioconductor.org/packages/release/bioc/html/GEOquery.html (Accessed 12/11)